

Vase Wiping3x playback1 / 3
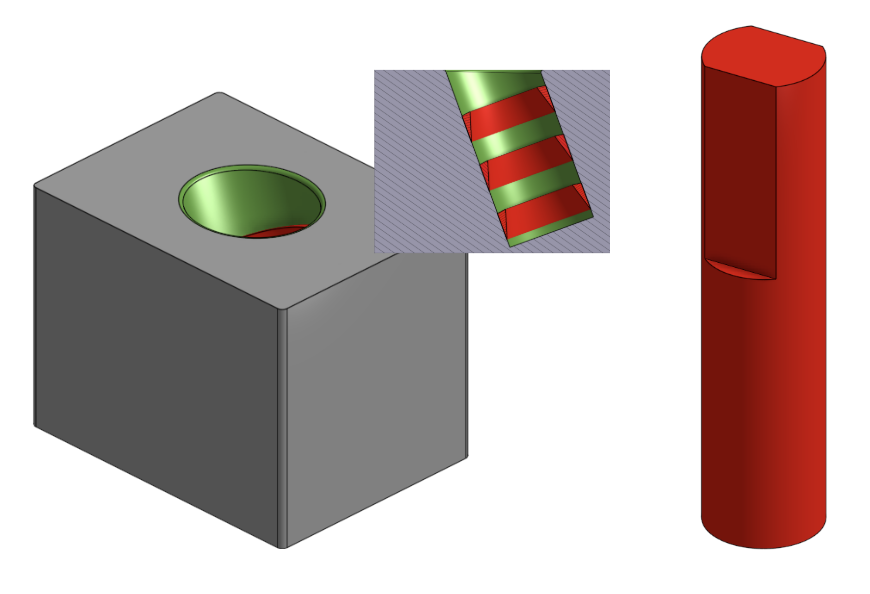
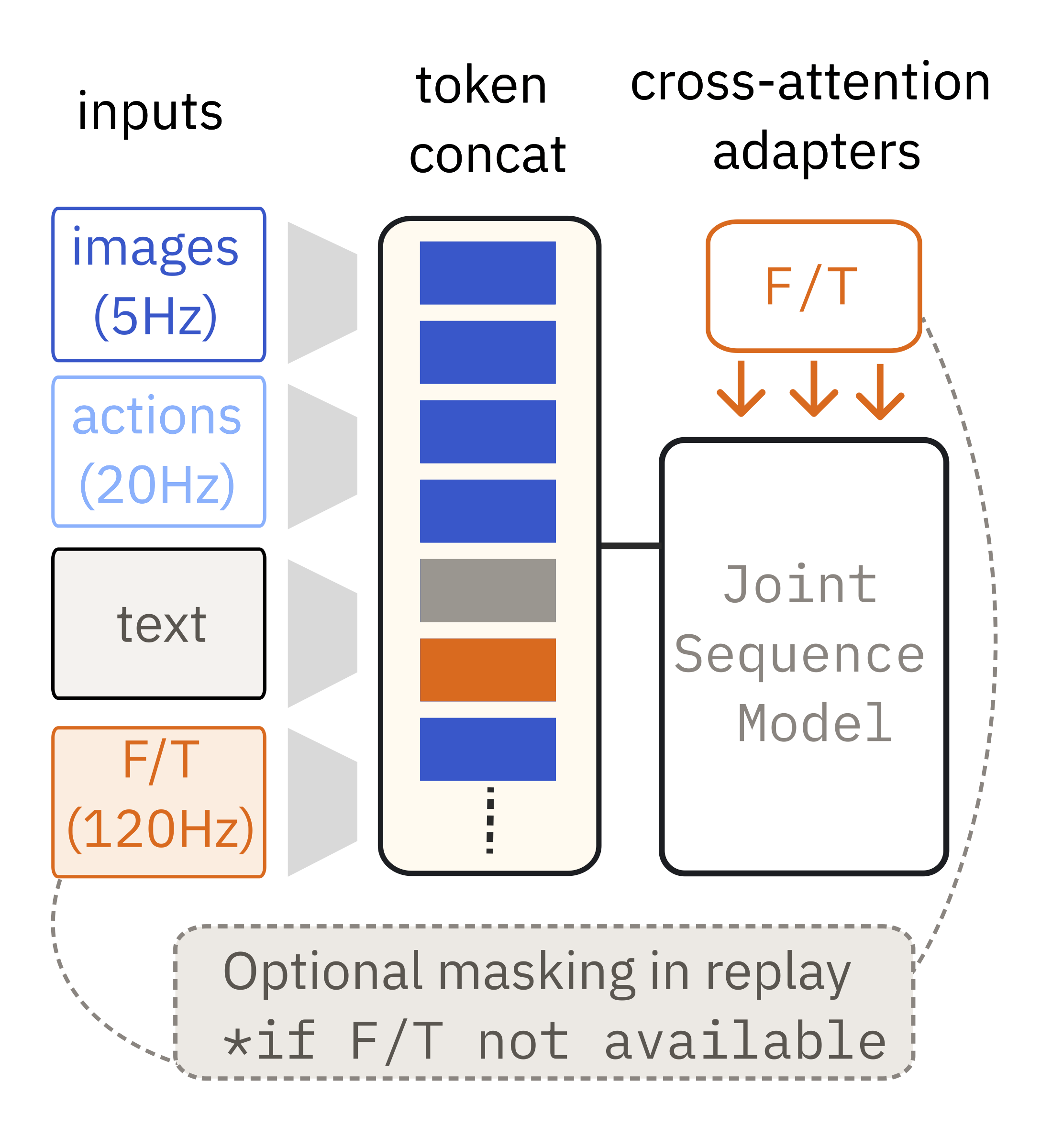
To wipe the vase, the policy leverages F/T sensing to sense when contact with the vase is made and adjusts its compliance to apply sufficient force to maintain contact and follow the curved surface, but not so much force that it jams into the vase and breaks the F/T limit set on the robot arm.
MuSe
77% successGeneralize to erasing orange drawing that doesn't exist in finetuning data.
Tracks the middle surface and regulates pressure through the wipe.
Generalize to a larger eraser without applying too much force.
Successfully wipes the vase with a larger eraser while maintaining safe contact.
- Use force feedback to maintain contact with the curved vase.
- Adjust compliance to maintain forceful but safe contact across drawing configurations and colors.
Less robust to different drawing appearances and vase variations.
Applies too little force, leaving the drawing partially unerased.
Fails to generalize to an out-of-distribution orange drawing.
Gets stuck against the vase after reaching the F/T safety limit.
- Fail to generalize to unseen drawings and vase variations without pretraining.
- Apply insufficient force or exceed the F/T safety limit without force feedback.